Update views.py Update tests.py Update source.html Update tasks.py Update signals.py Update 0001_initial.py Update models.py Update models.py Update tests.py
TubeSync
This is a preview release of TubeSync, it may contain bugs but should be usable
TubeSync is a PVR (personal video recorder) for YouTube. Or, like Sonarr but for YouTube (with a built-in download client). It is designed to synchronize channels and playlists from YouTube to local directories and update your media server once media is downloaded.
If you want to watch YouTube videos in particular quality or settings from your local
media server, then TubeSync is for you. Internally, TubeSync is a web interface wrapper
on yt-dlp and ffmpeg with a task scheduler.
There are several other web interfaces to YouTube and yt-dlp all with varying
features and implementations. TubeSync's largest difference is full PVR experience of
updating media servers and better selection of media formats. Additionally, to be as
hands-free as possible, TubeSync has gradual retrying of failures with back-off timers
so media which fails to download will be retried for an extended period making it,
hopefully, quite reliable.
Latest container image
ghcr.io/meeb/tubesync:latest
Screenshots
Dashboard

Sources overview

Source details

Media overview
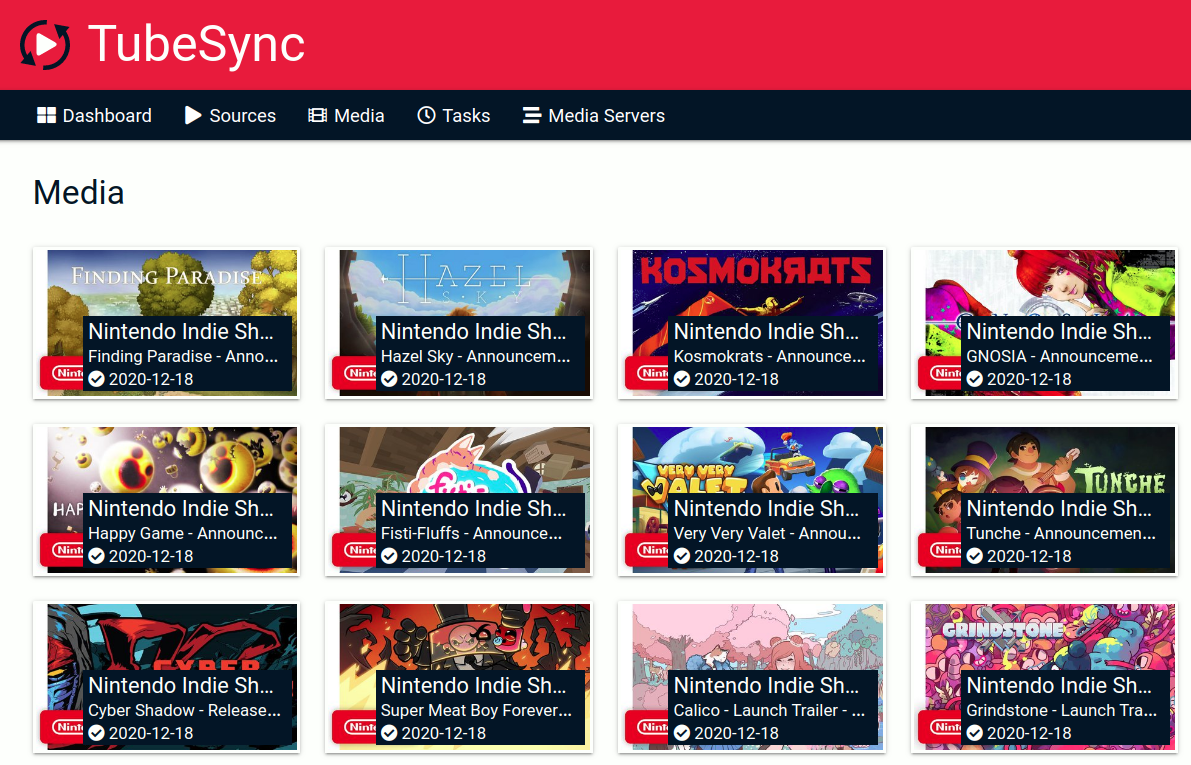
Media details

Requirements
For the easiest installation, you will need an environment to run containers such as Docker or Podman. You will also need as much space as you want to allocate to downloaded media and thumbnails. If you download a lot of media at high resolutions this can be very large.
What to expect
Once running, TubeSync will download media to a specified directory. Inside this
directory will be a video and audio subdirectories. All media which only has an
audio stream (such as music) will download to the audio directory. All media with a
video stream will be downloaded to the video directory. All administration of
TubeSync is performed via a web interface. You can optionally add a media server,
currently just Plex, to complete the PVR experience.
Installation
TubeSync is designed to be run in a container, such as via Docker or Podman. It also
works in a Docker Compose stack. amd64 (most desktop PCs and servers) and arm64
(modern ARM computers, such as the Rasperry Pi 3 or later) are supported.
Example (with Docker on *nix):
First find the user ID and group ID you want to run TubeSync as, if you're not sure what this is it's probably your current user ID and group ID:
$ id
# Example output, in this example, user ID = 1000, group ID = 1000
# id uid=1000(username) gid=1000(username) groups=1000(username),129(docker)
You can find your local timezone name here:
https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
If unset, TZ defaults to UTC.
Next, create the directories you're going to use for config data and downloads:
$ mkdir /some/directory/tubesync-config
$ mkdir /some/directory/tubesync-downloads
Finally, download and run the container:
# Pull image
$ docker pull ghcr.io/meeb/tubesync:latest
# Start the container using your user ID and group ID
$ docker run \
-d \
--name tubesync \
-e PUID=1000 \
-e PGID=1000 \
-e TZ=Europe/London \
-v /some/directory/tubesync-config:/config \
-v /some/directory/tubesync-downloads:/downloads \
-p 4848:4848 \
ghcr.io/meeb/tubesync:latest
Once running, open http://localhost:4848 in your browser and you should see the
TubeSync dashboard. If you do, you can proceed to adding some sources (YouTube channels
and playlists). If not, check docker logs tubesync to see what errors might be
occurring, typical ones are file permission issues.
Alternatively, for Docker Compose, you can use something like:
version: '3.7'
services:
tubesync:
image: ghcr.io/meeb/tubesync:latest
container_name: tubesync
restart: unless-stopped
ports:
- 4848:4848
volumes:
- /some/directory/tubesync-config:/config
- /some/directory/tubesync-downloads:/downloads
environment:
- TZ=Europe/London
- PUID=1000
- PGID=1000
Optional authentication
Available in v1.0 (or :latest)and later. If you want to enable a basic username and
password to be required to access the TubeSync dashboard you can set them with the
following environment variables:
HTTP_USER
HTTP_PASS
For example, in the docker run ... line add in:
...
-e HTTP_USER=some-username \
-e HTTP_PASS=some-secure-password \
...
Or in your Docker Compose file you would add in:
...
environment:
- HTTP_USER=some-username
- HTTP_PASS=some-secure-password
...
When BOTH HTTP_USER and HTTP_PASS are set then basic HTTP authentication will be
enabled.
Updating
To update, you can just pull a new version of the container image as they are released.
$ docker pull ghcr.io/meeb/tubesync:v[number]
Back-end updates such as database migrations should be automatic.
Moving, backing up, etc.
TubeSync, when running in its default container, stores thumbnails, cache and its
SQLite database into the /config directory and wherever you've mapped that to on your
file system. Just copying or moving this directory and making sure the permissions are
correct is sufficient to move, back up or migrate your TubeSync install.
Using TubeSync
1. Add some sources
Pick your favourite YouTube channels or playlists, pop over to the "sources" tab, click whichever add button suits you, enter the URL and validate it. This process extracts the key information from the URL and makes sure it's a valid URL. This is the channel name for YouTube channels and the playlist ID for YouTube playlists.
You will then be presented with the initial add a source form where you can select all the features you want, such as how often you want to index your source and the quality of the media you want to download. Once happy, click "add source".
2. Wait
That's about it. All other actions are automatic and performed on timers by scheduled tasks. You can see what your TubeSync instance is doing on the "tasks" tab.
As media is indexed and downloaded it will appear in the "media" tab.
3. Media Server updating
Currently TubeSync supports Plex as a media server. You can add your local Plex server under the "media servers" tab.
Logging and debugging
TubeSync outputs useful logs, errors and debugging information to the console. You can view these with:
$ docker logs --follow tubesync
Advanced usage guides
Once you're happy using TubeSync there are some advanced usage guides for more complex and less common features:
- Import existing media into TubeSync
- Sync or create missing metadata files
- Reset tasks from the command line
- Using PostgreSQL, MySQL or MariaDB as database backends
- Using cookies
- Reset metadata
Warnings
1. Index frequency
It's a good idea to add sources with as long of an index frequency as possible. This is the duration between indexes of the source. An index is when TubeSync checks to see what videos available on a channel or playlist to find new media. Try and keep this as long as possible, up to 24 hours.
2. Indexing massive channels
If you add a massive (several thousand videos) channel to TubeSync and choose "index every hour" or similar short interval it's entirely possible your TubeSync install may spend its entire time just indexing the massive channel over and over again without downloading any media. Check your tasks for the status of your TubeSync install.
If you add a significant amount of "work" due to adding many large channels you may
need to increase the number of background workers by setting the TUBESYNC_WORKERS
environment variable. Try around ~4 at most, although the absolute maximum allowed is 8.
Be nice. it's likely entirely possible your IP address could get throttled by the source if you try and crawl extremely large amounts very quickly. Try and be polite with the smallest amount of indexing and concurrent downloads possible for your needs.
FAQ
Can I use TubeSync to download single videos?
No, TubeSync is designed to repeatedly scan and download new media from channels or playlists. If you want to download single videos the best suggestion would be to create your own playlist, add the playlist to TubeSync and then add single videos to your playlist as you browse about YouTube. Your "favourites" playlist of videos will download automatically.
Does TubeSync support any other video platforms?
At the moment, no. This is a pre-release. The library TubeSync uses that does most
of the downloading work, yt-dlp, supports many hundreds of video sources so it's
likely more will be added to TubeSync if there is demand for it.
Is there a progress bar?
No, in fact, there is no JavaScript at all in the web interface at the moment. TubeSync is designed to be more set-and-forget than something you watch download. You can see what active tasks are being run in the "tasks" tab and if you want to see exactly what your install is doing check the container logs.
Are there alerts when a download is complete?
No, this feature is best served by existing services such as the excellent Tautulli which can monitor your Plex server and send alerts that way.
There are errors in my "tasks" tab!
You only really need to worry about these if there is a permanent failure. Some errors are temporary and will be retried for you automatically, such as a download got interrupted and will be tried again later. Sources with permanent errors (such as no media available because you got a channel name wrong) will be shown as errors on the "sources" tab.
What is TubeSync written in?
Python3 using Django, embedding yt-dlp. It's pretty much glue between other much larger libraries.
Notable libraries and software used:
- Django
- yt-dlp
- ffmpeg
- Django Background Tasks
- django-sass
- The container bundles with
s6-initandnginx
See the Pipefile for a full list.
Can I get access to the full Django admin?
Yes, although pretty much all operations are available through the front-end interface and you can probably break things by playing in the admin. If you still want to access it you can run:
$ docker exec -ti tubesync python3 /app/manage.py createsuperuser
And follow the instructions to create an initial Django superuser, once created, you can log in at http://localhost:4848/admin
Are there user accounts or multi-user support?
There is support for basic HTTP authentication by setting the HTTP_USER and
HTTP_PASS environment variables. There is not support for multi-user or user
management.
Does TubeSync support HTTPS?
No, you should deploy it behind an HTTPS-capable proxy if you want this (nginx, caddy, etc.). Configuration of this is beyond the scope of this README.
What architectures does the container support?
Just amd64 for the moment. Others may be made available if there is demand.
The pipenv install fails with "Locking failed"!
Make sure that you have mysql_config or mariadb_config available, as required by the python module mysqlclient. On Debian-based systems this is usually found in the package libmysqlclient-dev
Advanced configuration
There are a number of other environment variables you can set. These are, mostly, NOT required to be set in the default container installation, they are really only useful if you are manually installing TubeSync in some other environment. These are:
| Name | What | Example |
|---|---|---|
| DJANGO_SECRET_KEY | Django's SECRET_KEY | YJySXnQLB7UVZw2dXKDWxI5lEZaImK6l |
| DJANGO_URL_PREFIX | Run TubeSync in a sub-URL on the web server | /somepath/ |
| TUBESYNC_DEBUG | Enable debugging | True |
| TUBESYNC_WORKERS | Number of background workers, default is 2, max allowed is 8 | 2 |
| TUBESYNC_HOSTS | Django's ALLOWED_HOSTS, defaults to * |
tubesync.example.com,otherhost.com |
| TUBESYNC_RESET_DOWNLOAD_DIR | Toggle resetting /downloads permissions, defaults to True |
True |
| GUNICORN_WORKERS | Number of gunicorn workers to spawn | 3 |
| LISTEN_HOST | IP address for gunicorn to listen on | 127.0.0.1 |
| LISTEN_PORT | Port number for gunicorn to listen on | 8080 |
| HTTP_USER | Sets the username for HTTP basic authentication | some-username |
| HTTP_PASS | Sets the password for HTTP basic authentication | some-secure-password |
| DATABASE_CONNECTION | Optional external database connection details | mysql://user:pass@host:port/database |
Manual, non-containerised, installation
As a relatively normal Django app you can run TubeSync without the container. Beyond following this rough guide, you are on your own and should be knowledgeable about installing and running WSGI-based Python web applications before attempting this.
- Clone or download this repo
- Make sure you're running a modern version of Python (>=3.6) and have Pipenv installed
- Set up the environment with
pipenv install - Copy
tubesync/tubesync/local_settings.py.exampletotubesync/tubesync/local_settings.pyand edit it as appropriate - Run migrations with
./manage.py migrate - Collect static files with
./manage.py collectstatic - Set up your prefered WSGI server, such as
gunicornpointing it to the application intubesync/tubesync/wsgi.py - Set up your proxy server such as
nginxand forward it to the WSGI server - Check the web interface is working
- Run
./manage.py process_tasksas the background task worker to index and download media. This is a non-detaching process that will write logs to the console. For long term running you could use a terminal multiplexer such astmux, or createsystemdunit to run it.
Tests
There is a moderately comprehensive test suite focusing on the custom media format matching logic and that the front-end interface works. You can run it via Django:
$ ./manage.py test --verbosity=2
Contributing
All properly formatted and sensible pull requests, issues and comments are welcome.